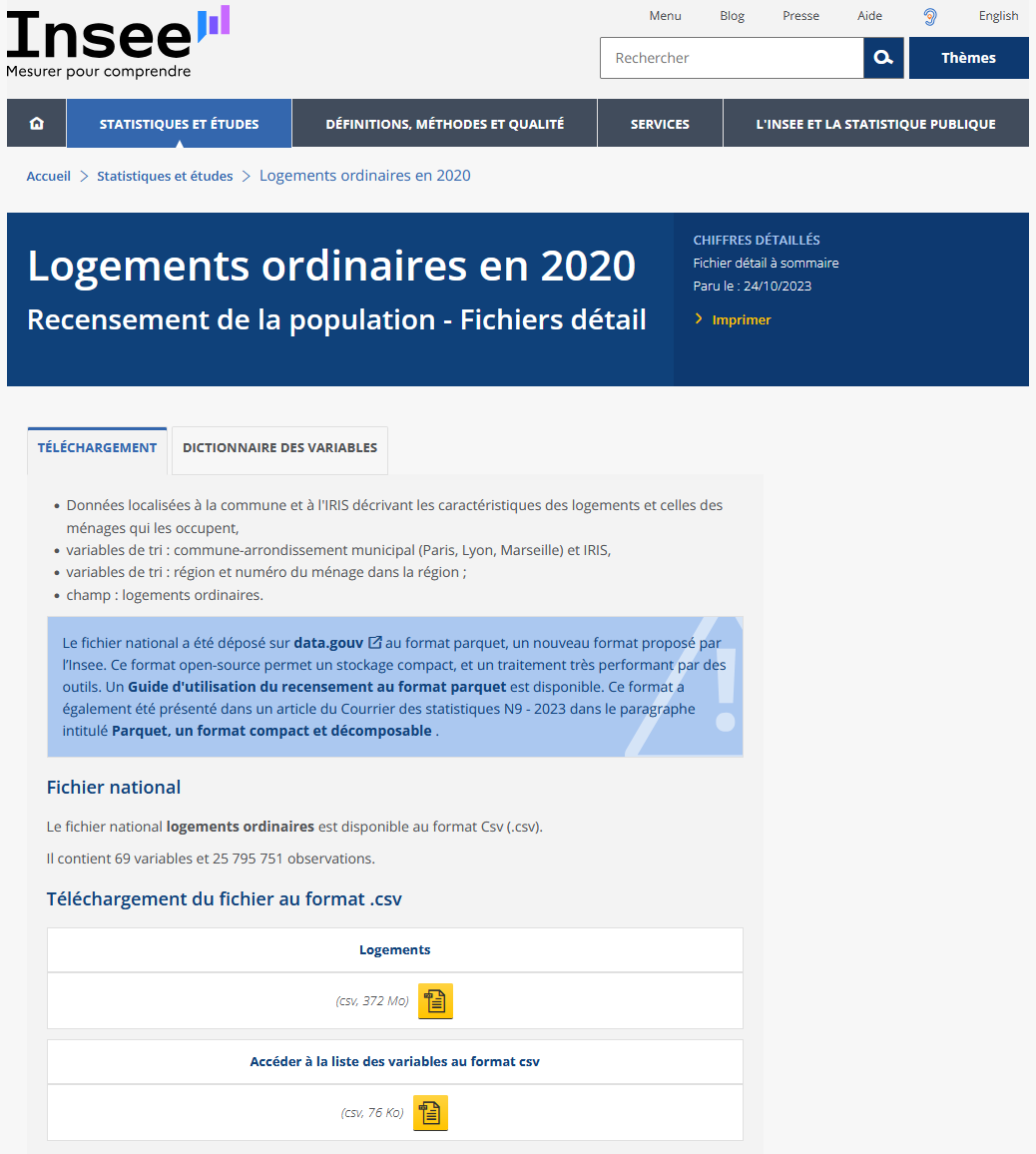
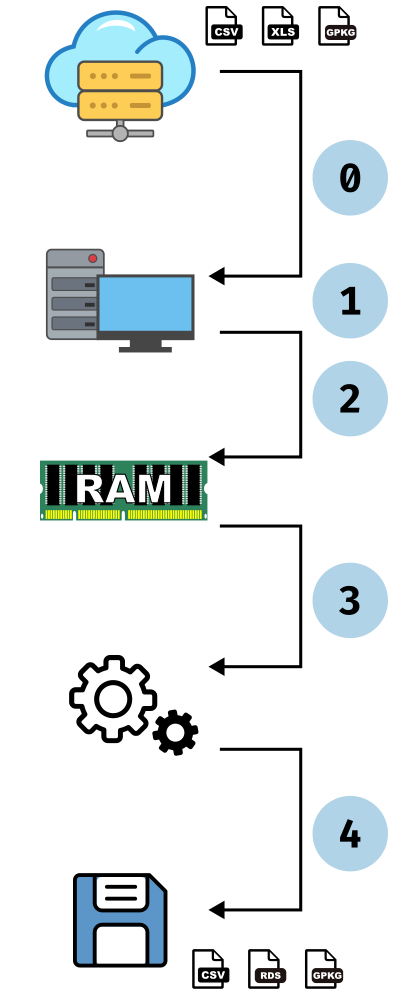
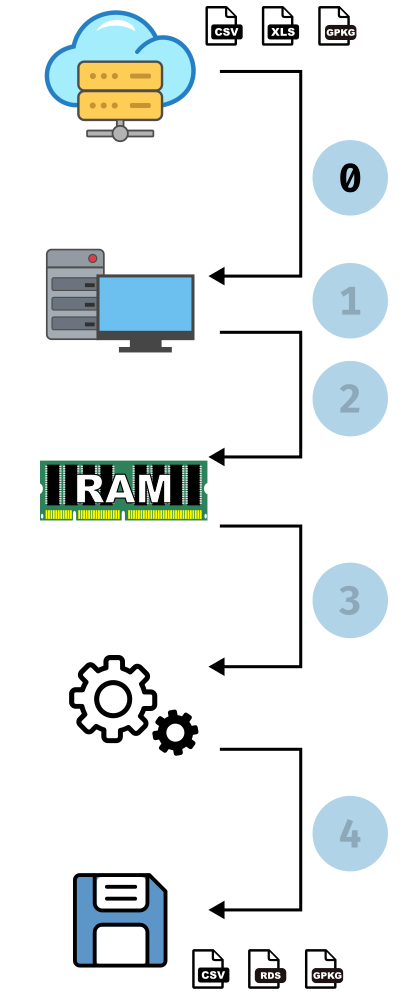
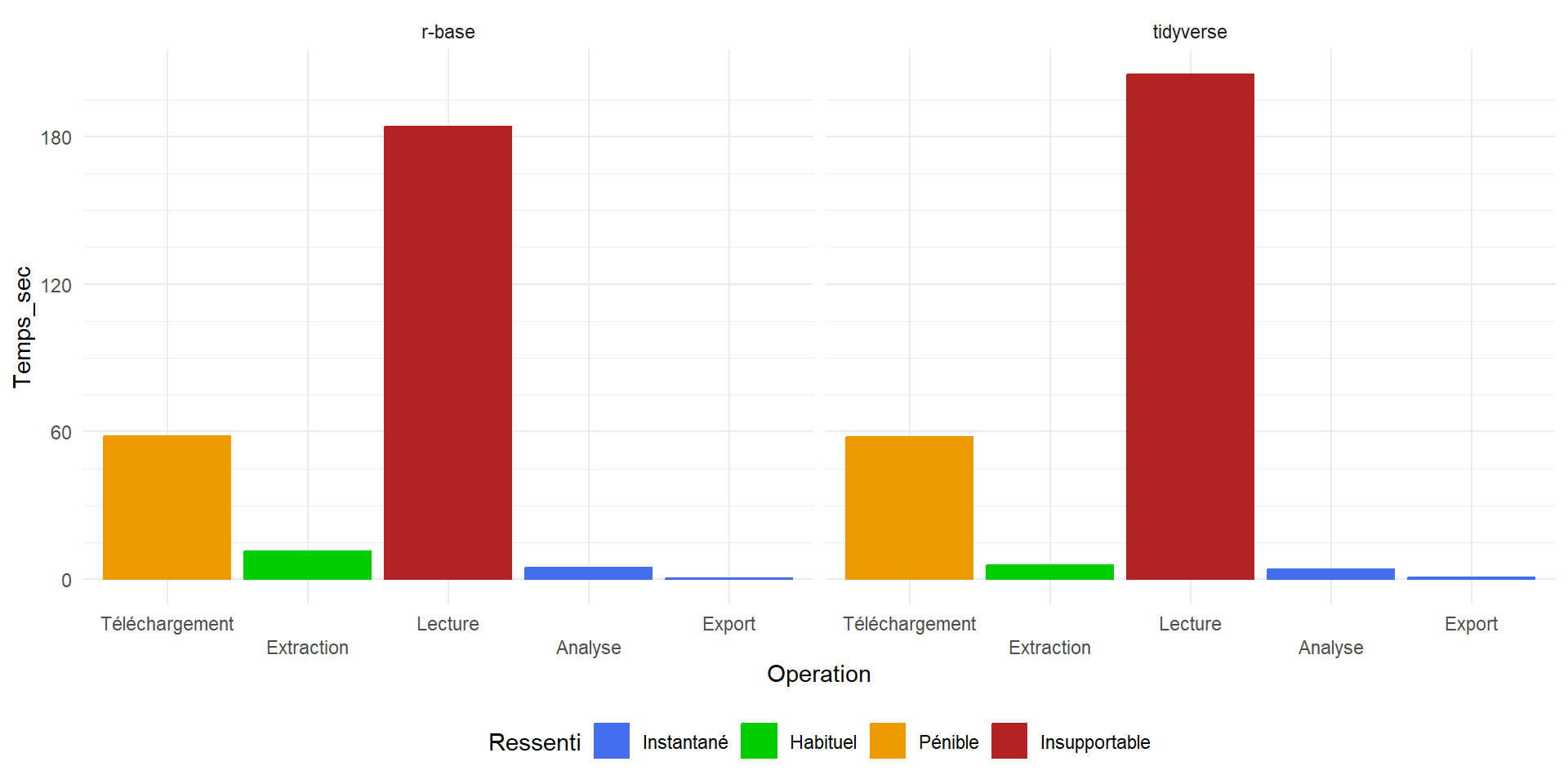
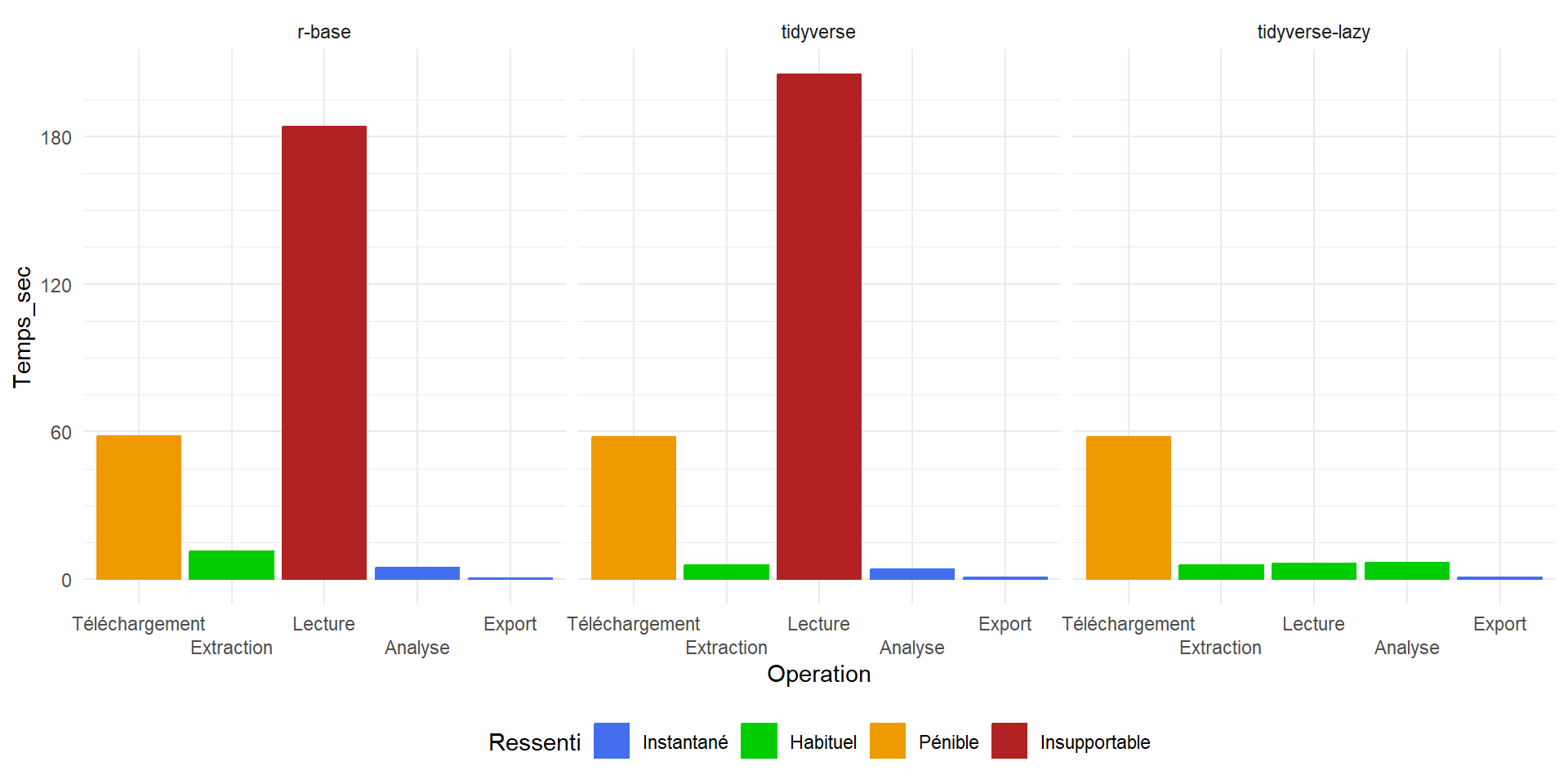
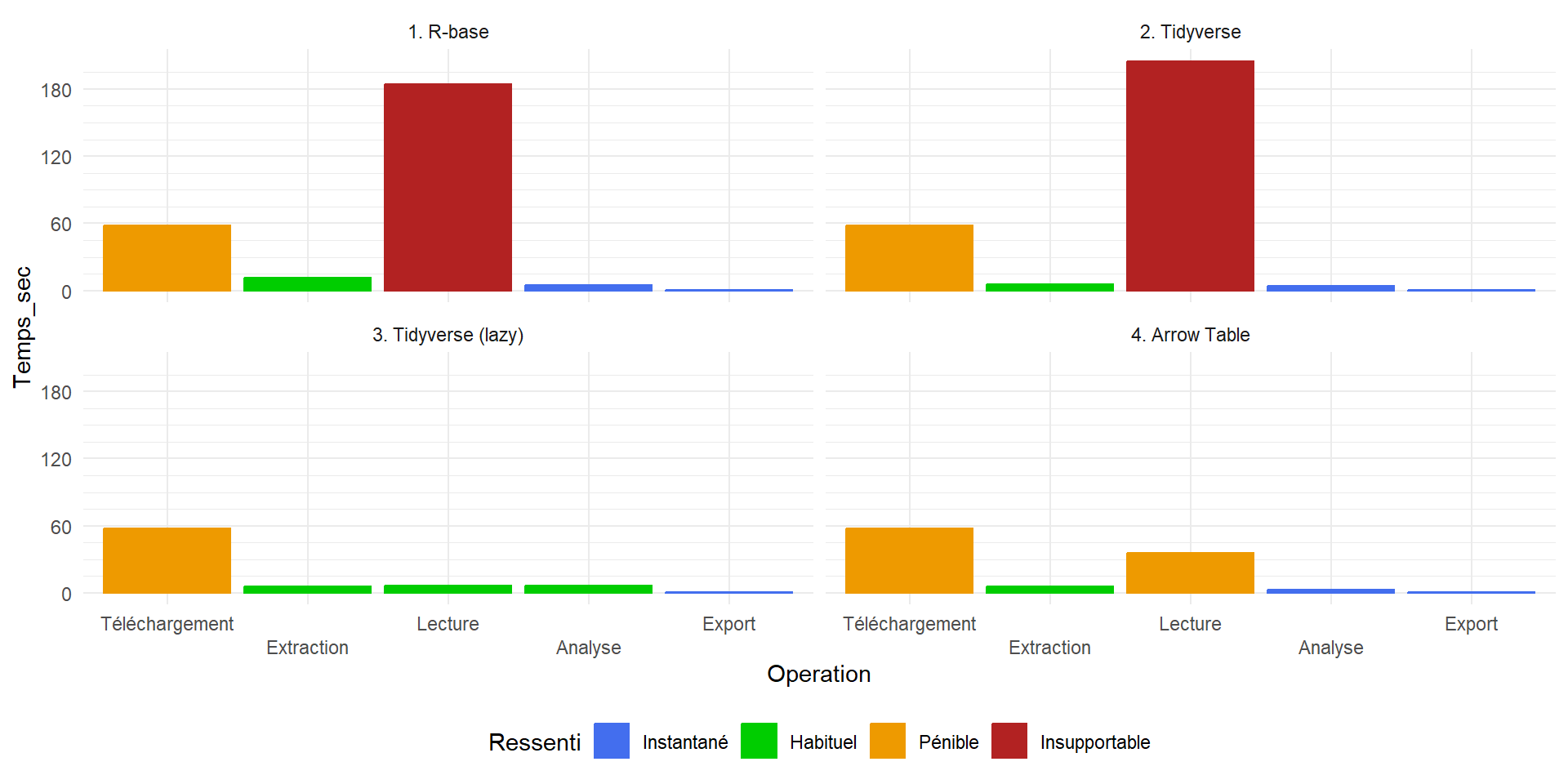
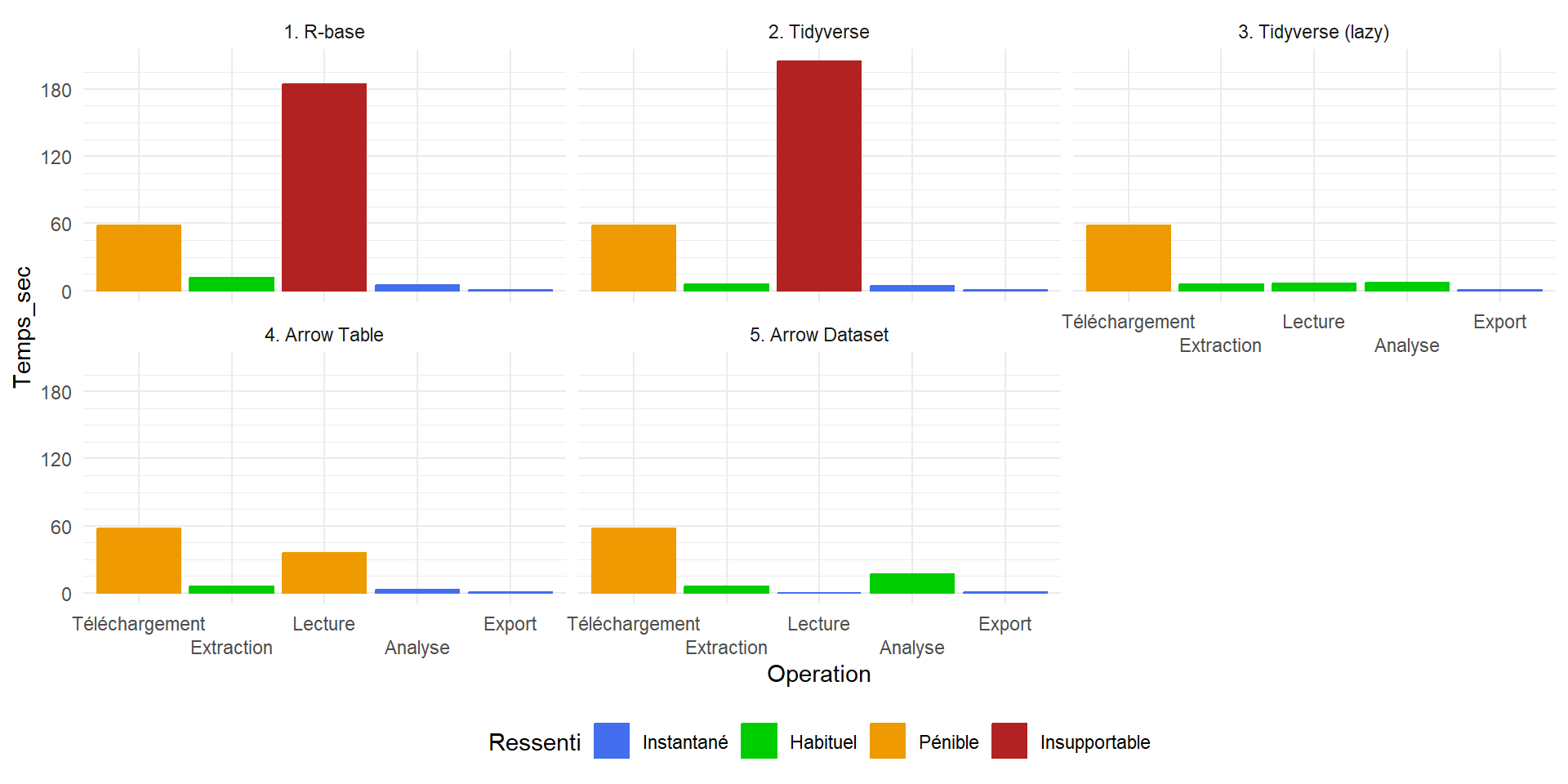
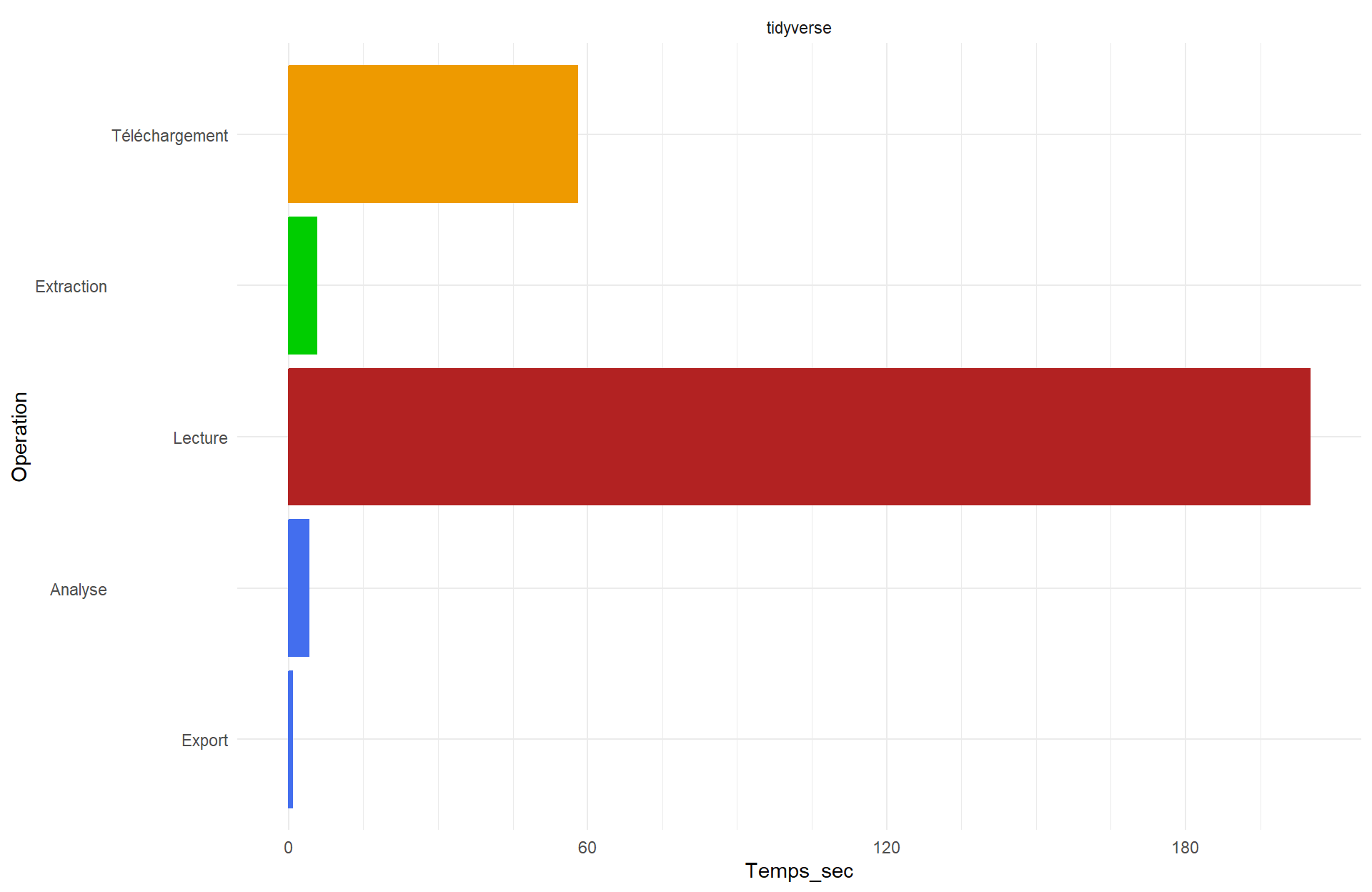Pour chaque commune de France, on cherche à récupérer le nombre de logements, leur distribution selon le type de logement (appartement, maison, etc.) et selon la catégorie de logement (résidence principale, secondaire, logement vacant, etc.).
Un exemple d’analyse
Téléchargement du fichier
Extraction de l’archive
Lecture dans R
Traitement : récupérer, pour chaque commune, le nombre de logements et le détail de leurs types (maison, appartement, etc.) et de leur catégorie (résidence principale, secondaire, vacant etc.)
Export du fichier résumé
Un exemple d’analyse
Téléchargement du fichier
options(timeout=600) # Permettre le téléchargement jusqu'à 10 minutesfile_url <-"https://www.insee.fr/fr/statistiques/fichier/7705908/RP2020_LOGEMT_csv.zip"download.file(url = file_url, destfile ="data/RP2020_LOGEMT_csv.zip")
Des traitements faisables tant qu’on a assez de mémoire vive
Pour toutes les méthodes présentées jusque là, ce “simple” fichier CSV de 4.5 Go occupe 13 Go de RAM
Ça ne marchera pas sur un ordinateur ayant moins de 16 Go de RAM, et avec difficulté…
Un format de sérialisation plus performant
Apache Arrow is a language-agnostic software framework for developing data analytics applications that process columnar data. It contains a standardized column-oriented memory format that is able to represent flat and hierarchical data for efficient analytic operations on modern CPU and GPU hardware. Wikipedia, 2025
Dans une chaîne de traitement dplyr habituelle, le collect() n’a aucun effet et n’entraîne pas d’erreur : laisser des collect() n’entraîne aucun risque, ils sont ignorés.
Petit récapitulatif
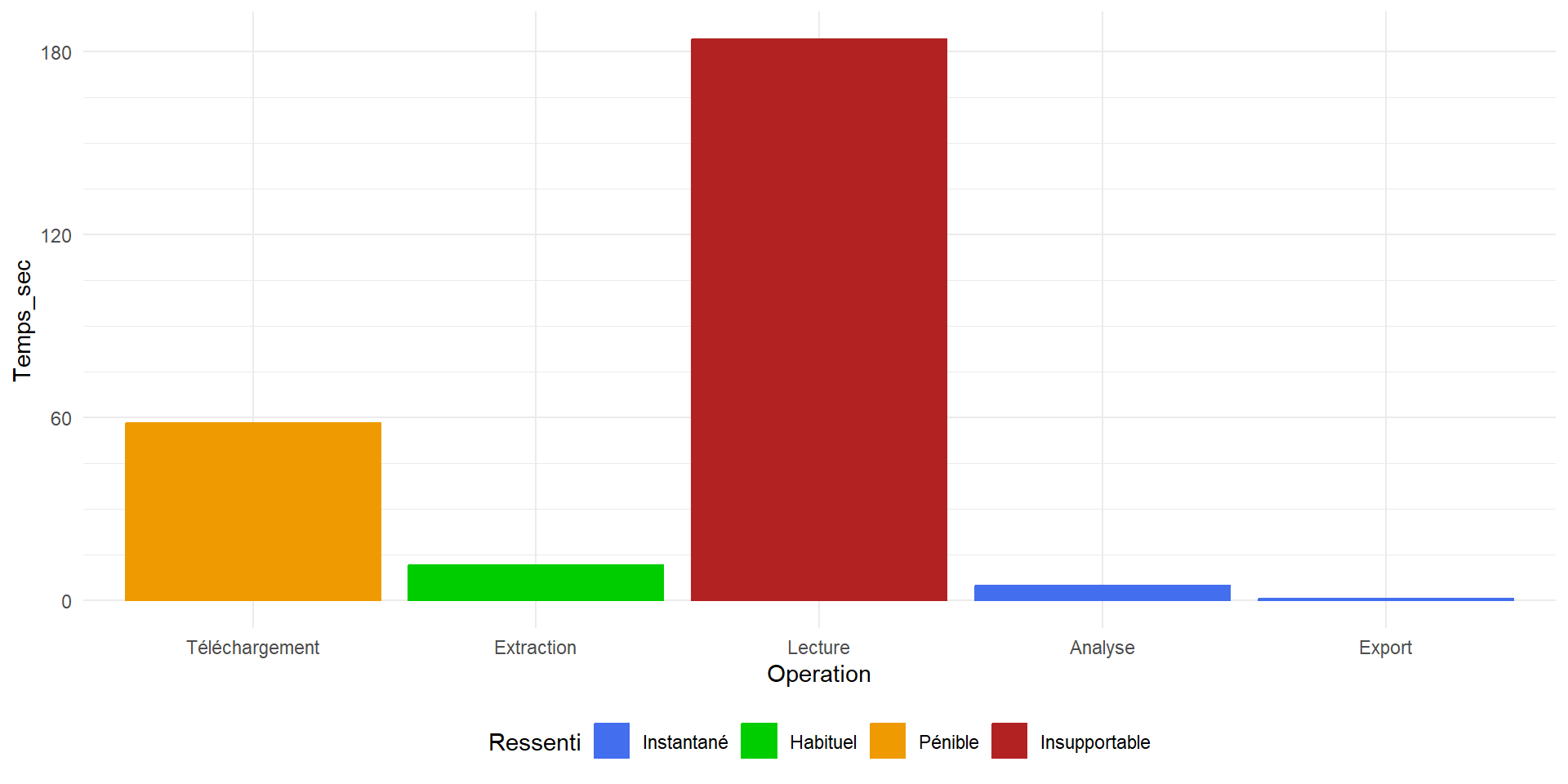
Le temps de lecture est encore pénible.
On ne pourrait pas aussi avoir une logique d’indexation du fichier sans le charger ?
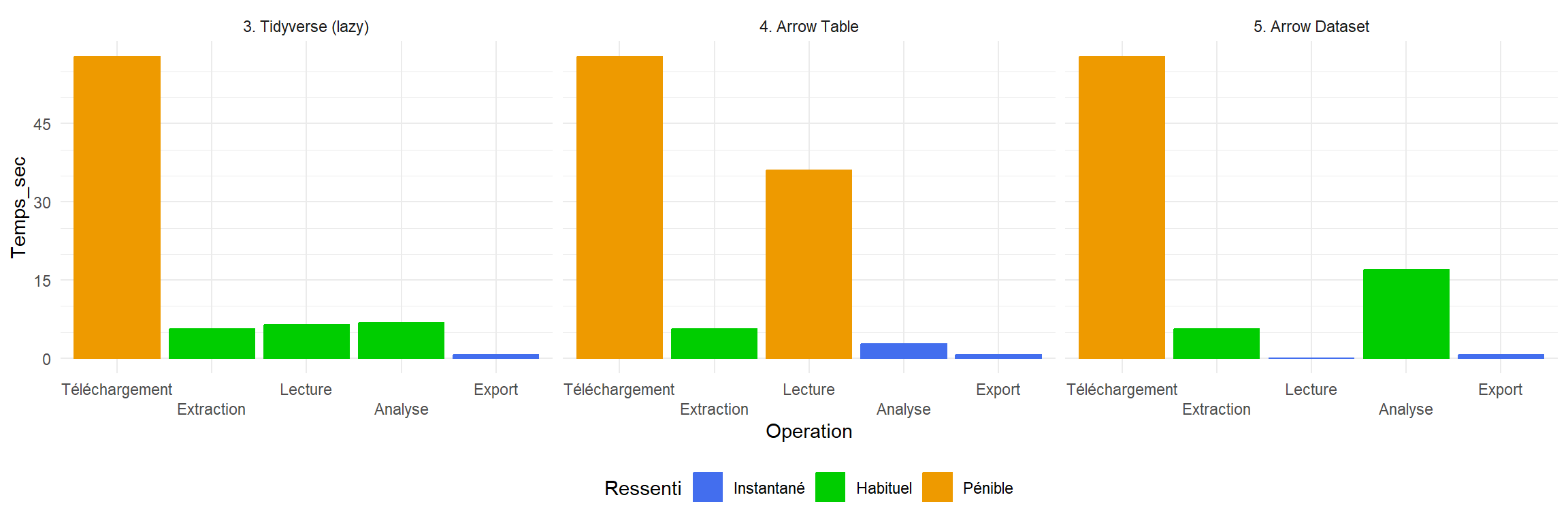
Les Dataset Arrow
Pour interroger et manipuler des fichiers sans les charger en mémoire, Arrow propose d’utiliser des Arrow Dataset à la place des Arrow Table
Error in `arrow_not_supported()`:
! Slicing grouped data not supported in Arrow
rp2020_table %>%group_by(COMMUNE) %>%slice_max(NBPI, n =1)
Error in `arrow_not_supported()`:
! Slicing grouped data not supported in Arrow
Le problème avec arrow
rp2020_dataset %>%group_by(COMMUNE) %>%slice_max(NBPI, n =1)
Error in `arrow_not_supported()`:
! Slicing grouped data not supported in Arrow
Arrow permet de stocker des tableaux en mémoire et des les interroger avec des fonctionnalités spécifiques.
Toutes les fonctions de dplyr ne sont pas intégrées dans arrow, notamment les fonctions “fenêtrées” (window function).
Arrow est un formidable outil pour manipuler/agréger des données (très) massives avec une empreinte mémoire extrêmement réduite, mais c’est avant tout un format de données en mémoire vive, qui sert de base à de nombreux autres outils.
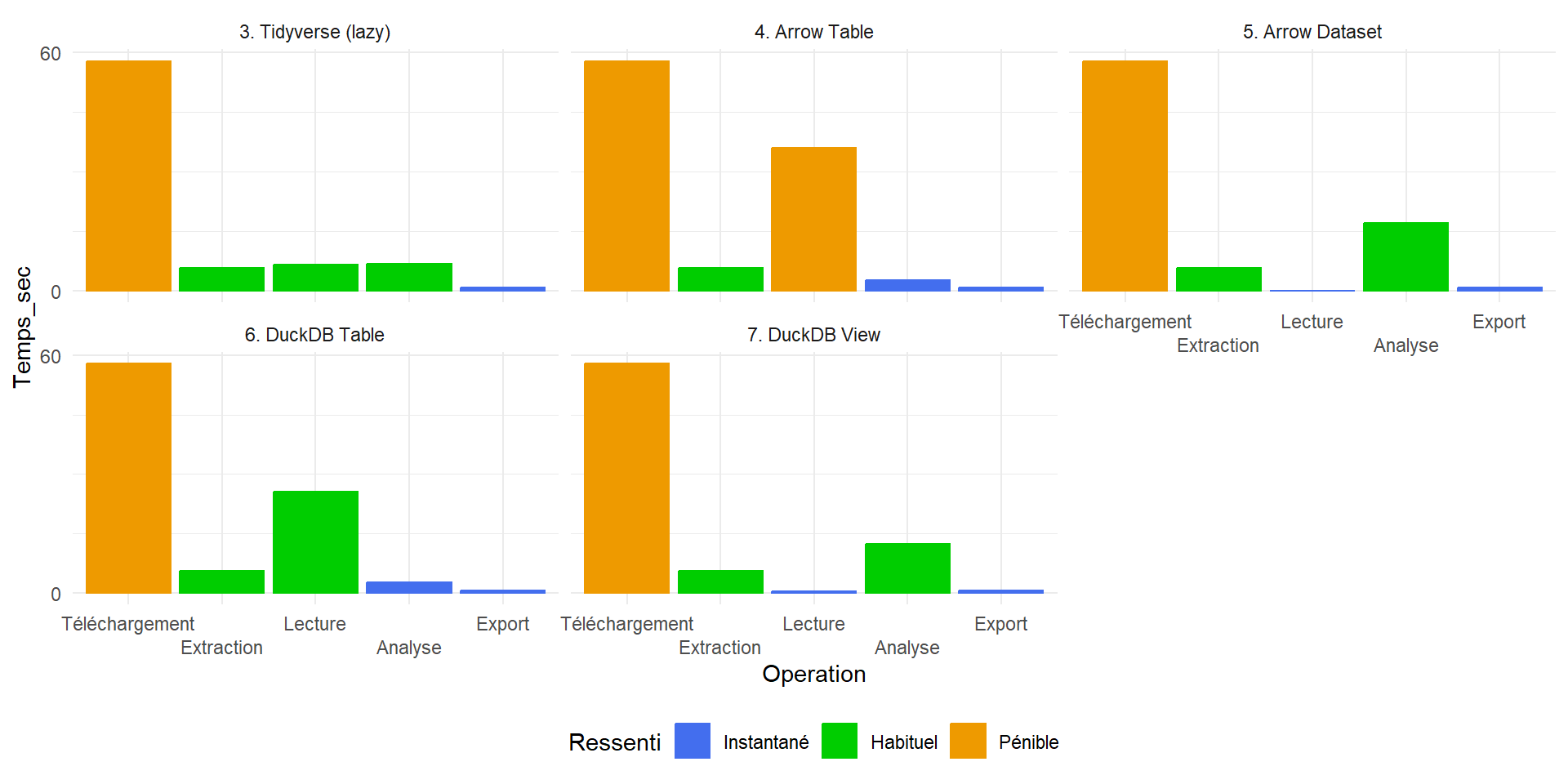
Un outil versatile et performant d’analyse de données massives : DuckDB
DuckDB is an open-source column-oriented Relational Database Management System (RDBMS). It is designed to provide high performance on complex queries against large databases in embedded configuration, such as combining tables with hundreds of columns and billions of rows. Wikipedia, 2025
dbSendQuery(con, "CREATE TABLE rp2020 AS SELECT * FROM read_csv('data/FD_LOGEMT_2020.csv', delim = ';')")
Statistiques - Lecture
: 25.56 sec
: 15 Go
Utilisation de DuckDB en SQL
Avec ce format natif, on va se contenter d’utiliser R pour exécuter des requêtes SQL :
dbSendQuery(con,"CREATE TABLE resume_commune ASSELECT COMMUNE, CATL, TYPL, COUNT(*) as nb_logementsFROM rp2020GROUP BY COMMUNE, CATL, TYPL;")dbSendQuery(con,"CREATE TABLE resume_CATL ASSELECT COMMUNE, CATL, SUM(nb_logements) as nb_logementsFROM resume_communeGROUP BY COMMUNE, CATL;")dbSendQuery(con,"CREATE TABLE resume_TYPL ASSELECT COMMUNE, TYPL, SUM(nb_logements) as nb_logementsFROM resume_communeGROUP BY COMMUNE, TYPL;")dbSendQuery(con, "CREATE TABLE resume_CATL_wide ASSELECTCOMMUNE,MAX(CASE WHEN (CATL = 1.0) THEN nb_logements WHEN NOT (CATL = 1.0) THEN 0.0 END) AS CATL_1,MAX(CASE WHEN (CATL = 2.0) THEN nb_logements WHEN NOT (CATL = 2.0) THEN 0.0 END) AS CATL_2,MAX(CASE WHEN (CATL = 3.0) THEN nb_logements WHEN NOT (CATL = 3.0) THEN 0.0 END) AS CATL_3,MAX(CASE WHEN (CATL = 4.0) THEN nb_logements WHEN NOT (CATL = 4.0) THEN 0.0 END) AS CATL_4FROM resume_CATLGROUP BY COMMUNE;")
dbSendQuery(con, "CREATE TABLE resume_TYPL_wide ASSELECTCOMMUNE,MAX(CASE WHEN (TYPL = 1.0) THEN nb_logements WHEN NOT (TYPL = 1.0) THEN 0.0 END) AS TYPL_1,MAX(CASE WHEN (TYPL = 2.0) THEN nb_logements WHEN NOT (TYPL = 2.0) THEN 0.0 END) AS TYPL_2,MAX(CASE WHEN (TYPL = 3.0) THEN nb_logements WHEN NOT (TYPL = 3.0) THEN 0.0 END) AS TYPL_3,MAX(CASE WHEN (TYPL = 4.0) THEN nb_logements WHEN NOT (TYPL = 4.0) THEN 0.0 END) AS TYPL_4,MAX(CASE WHEN (TYPL = 5.0) THEN nb_logements WHEN NOT (TYPL = 5.0) THEN 0.0 END) AS TYPL_5,MAX(CASE WHEN (TYPL = 6.0) THEN nb_logements WHEN NOT (TYPL = 6.0) THEN 0.0 END) AS TYPL_6FROM resume_TYPLGROUP BY COMMUNE")dbSendQuery(con, "CREATE TABLE resume_commune_2 ASSELECT COMMUNE, SUM(nb_logements) AS LOGEMENTS_TOTALFROM resume_communeGROUP BY COMMUNE;")dbSendQuery(con, "CREATE TABLE resume_global ASSELECT res2.COMMUNE, res2.LOGEMENTS_TOTAL,CATL_1, CATL_2, CATL_3, CATL_4,TYPL_1, TYPL_2, TYPL_3, TYPL_4, TYPL_5, TYPL_6FROM resume_commune_2 res2LEFT JOIN resume_CATL_wide catlON res2.COMMUNE = catl.COMMUNELEFT JOIN resume_TYPL_wide typlON res2.COMMUNE = typl.COMMUNE;")
Utilisation de DuckDB en SQL
Comme pour arrow, on ne récupère le résultat final en “format R” qu’à la fin de notre chaîne de traitement, avec dbGetQuery
resume_global <-dbGetQuery(con, "SELECT * FROM resume_global")resume_global
Arrow est un format de données en mémoire, qui permet d’interroger des données massives rapidement et avec une empreinte mémoire très réduite mais des capacités inférieures à dplyr.
DuckDB est un système de gestion de bases de données en mémoire et propose ~ toutes les opérations de dplyr avec une empreinte mémoire très réduite et un temps de traitement très rapide.
Point d’étape
Avec ces deux systèmes concurrents*, on arrive à traiter très rapidement des données tabulaires importantes, avec deux voies alternatives :
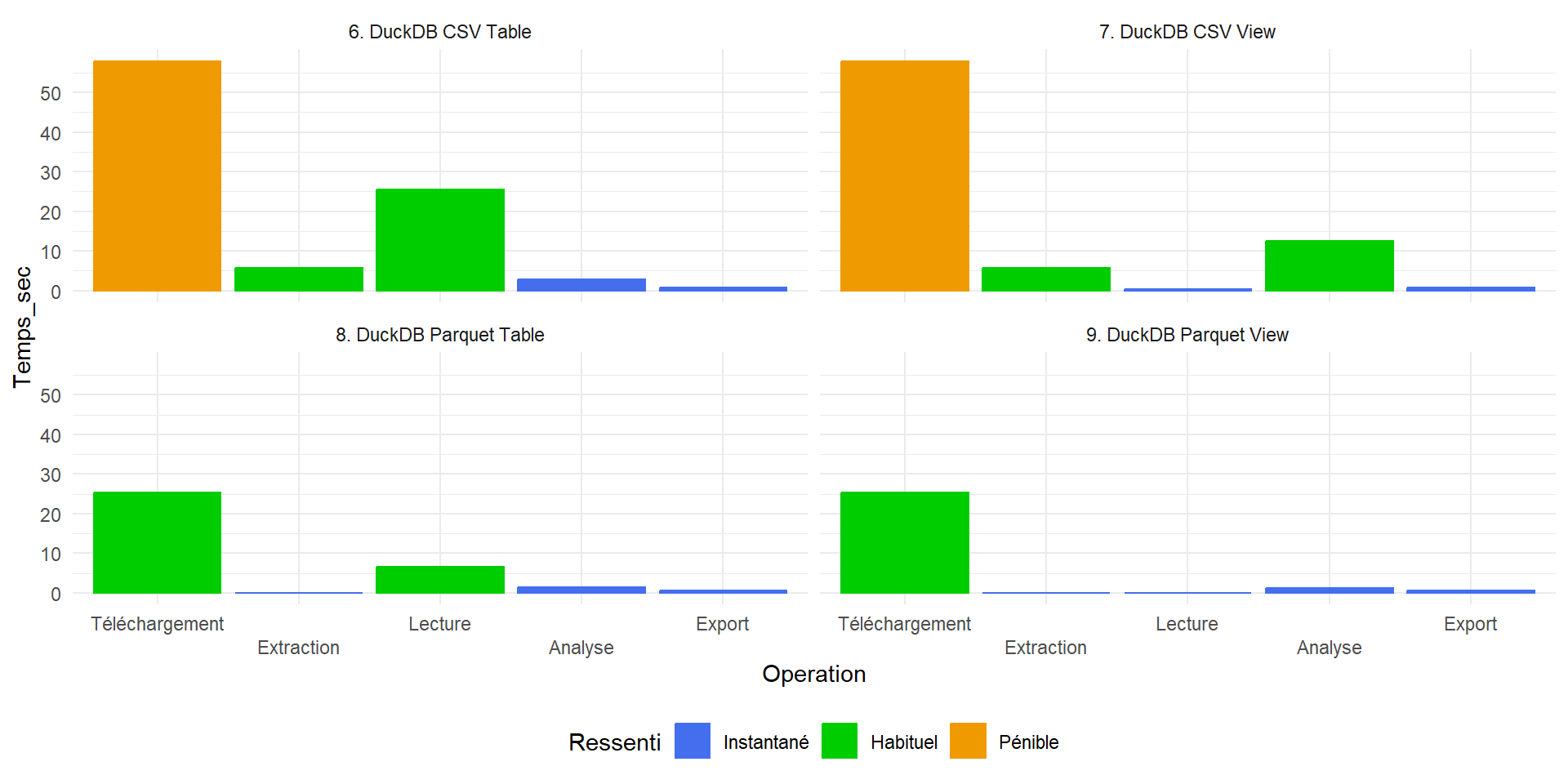
Lire entièrement le fichier en entrée (36 sec Arrow, 25 DuckDB) et l’analyser depuis la table créée (2.67 sec Arrow, 2.75 DuckDB)
Indexer le fichier (quasi instantanée) et l’analyser ensuite depuis le dataset/view générées (17 sec Arrow, 12 DuckDB)
Le choix de la méthode dépend du traitement voulu et de la taille des données :
si on doit faire de nombreux traitements successifs sur un même jeu de données et qu’il tient en mémoire vive, on le lit.
Sinon, on l’indexe.
Comment gagner encore du temps et des capacités à traiter de plus gros jeux de données ?
Réduire la taille des fichiers manipulés pour ne pas avoir à archiver/désarchiver les données
Accélérer la lecture des fichiers pour les traiter en mémoire
Accélérer le traitement de fichiers indexés
Se passer des phases de téléchargement
Comment gagner encore du temps et des capacités à traiter de plus gros jeux de données ?
Réduire la taille des fichiers manipulés pour ne pas avoir à archiver/désarchiver les données
Accélérer la lecture des fichiers pour les traiter en mémoire
Accélérer le traitement de fichiers indexés
Se passer des phases de téléchargement
Pour tout ça, il y a le format Parquet !
Apache Parquet
Apache Parquet est un format de fichiers orienté colonne, initialement développé pour l’écosystème de calcul distribué Apache Hadoop. […] Il fournit des schémas efficaces de compression et de codage de données avec des performances améliorées pour gérer des données complexes en masse. Wikipedia, 2025
Un format de données compressé, performant, et orienté colonne.
Apache Parquet
Un format de données compressé, performant, et orienté colonne.
Dans un fichier classique, l’information est organisée ligne par ligne, ce qui en rend simple l’ajout ou la suppression.
C’est le modèle utilisé dans les bases de données relationnelles et pour les fichiers qui seront amenés à être modifiés fréquemment : le plus important dans ce cas est de rapidement pouvoir ajouter des lignes, ou modifier une valeur spécifique d’une ligne définie.
Cela implique aussi que pour extraire une seule colonne d’un tableau, il faut lire ce tableau en entier puis reconstituer la colonne à partir de toutes les valeurs comprises dans les lignes.
De même si on veut ajouter une colonne dans un fichier : il faut lire toutes les lignes et ajouter la valeur à la fin de chacune.
Orienté colonne ?
Pour un usage “analytique”, on utilise plus souvent une organisation orientée colonne
Voir par exemple la manière dont un data.frame est organisé en R :
Que ce soit pour l’organisation d’un tableau en mémoire ou dans sa matérialisation en fichier, un jeu de données orienté colonne permet donc une interrogation plus rapide de chaque colonne, mais aussi :
De ne pas lire tout un jeu de données pour extraire une seule colonne
C’est pour cela (entre autre) que DuckDB et Arrow traitent plus rapidement l’information
Orienté colonne ?
Que ce soit pour l’organisation d’un tableau en mémoire ou dans sa matérialisation en fichier, un jeu de données orienté colonne permet donc une interrogation plus rapide de chaque colonne, mais aussi :
De faciliter la compression des informations
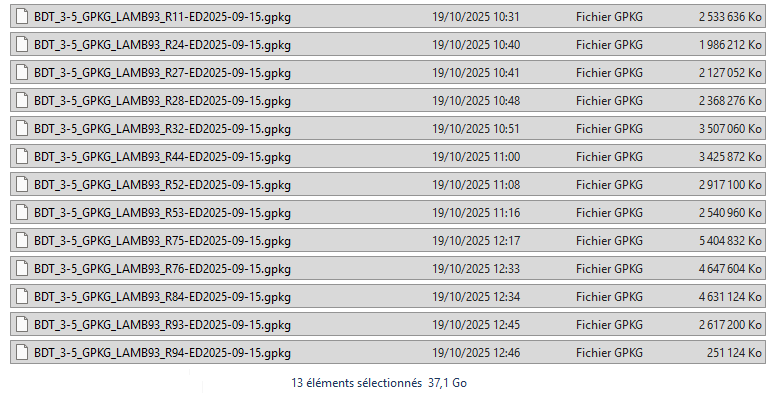
Les fichiers orientés colonnes, quand le nombre de lignes est important, sont toujours plus légers que leurs homologues orientés lignes.
Exemple sur la couche des bâtiments de la BD TOPO :
Revenons à notre exemple de chaîne de traitement
L’INSEE propose désormais, pour certains jeux de données récents, un export au format Parquet :
Les fichiers parquet sont organisés en colonne et disposent de métadonnées extrêmement efficaces qui les rendent utilisable en streaming : pour interroger une seule colonne, on n’a pas besoin de lire tout le fichier, et on n’a pas besoin non plus de le télécharger dans son entièreté
Une dernière chose
Pour interroger un fichier en ligne sans le télécharger, DuckDB propose une extension httpfs :
library(duckdb)library(glue)con <-dbConnect(duckdb())dbSendQuery(con, "INSTALL httpfs;")dbSendQuery(con, "LOAD httpfs;")url_parquet <-"https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-logements-ordinaires-en-2020-1/20231023-123618/fd-logemt-2020.parquet"dbSendQuery(con, glue("CREATE OR REPLACE VIEW rp2020 AS SELECT * FROM read_parquet('{url_parquet}');"))rp2020 <-tbl(con, "rp2020")
Une dernière chose
0-3. Chaîne de traitement complète
Statistiques
: 0.22 sec (connexion) + 1.25 sec (analyse)
: ~300 Mo en pic
: ~230 Ko pour l’indexation + 9 Mo pour l’analyse
Une dernière chose
Au lieu de télécharger les 481 Mo du fichier Parquet en ligne, on lui a demandé uniquement ce qui était nécessaire pour l’analyse à mener : 9 Mo
Temps initial (R base) d’analyse complète : 258 secondes
Temps final avec un fichier Parquet indexé et interrogé via DuckDB : 1.47 secondes
Au delà de la rapidité, DuckDB et Arrow permettent surtout de travailler sur des jeux de données bien plus importants que la mémoire vive de votre ordinateur ne devrait le permettre
Un exemple d’analyse sur un jeu de données très massif
library(tidyverse)library(duckdb)# Chargement de l'extension httpfs pour lire des fichiers parquets distantscon <-dbConnect(duckdb())dbSendQuery(con, "INSTALL httpfs;")dbSendQuery(con, "LOAD httpfs;")# Récupération des liens vers les fichiers parquet distant : couche des bâtiments de la BD TOPOlibrary(rvest)bati_files <-read_html("https://analytics.huma-num.fr/Robin.Cura/ElementR_DonneesMassives/BATI_BDTOPO/") %>%html_elements("a") %>%html_attr("href")# Construction de la syntaxe attendue : ['https://url1', 'https://url2 etc.']files_array <- bati_files %>%paste0("'https://analytics.huma-num.fr/Robin.Cura/ElementR_DonneesMassives/BATI_BDTOPO/", ., "'") %>%paste0(collapse =",\n") %>%paste0('[', ., ']')cat(files_array)
Un exemple d’analyse sur un jeu de données très massif
library(glue)# Création de la VIEW se connectant aux 13 fichiers bâti et connexiondbSendQuery(con, glue("CREATE OR REPLACE VIEW bati AS SELECT * FROM read_parquet({files_array});"))bati_distant <-tbl(con, "bati")bati_distant
# Source: table<bati> [?? x 31]
# Database: DuckDB v1.3.0 [robin@Windows 10 x64:R 4.5.1/:memory:]
cleabs nature usage_1 usage_2 construction_legere etat_de_l_objet
<chr> <chr> <chr> <chr> <lgl> <chr>
1 BATIMENT000000033… Indif… Sportif <NA> FALSE En service
2 BATIMENT000000033… Indif… Sportif Commer… FALSE En service
3 BATIMENT000000033… Indif… Sportif Commer… FALSE En service
4 BATIMENT000000033… Indif… Sportif Réside… FALSE En service
5 BATIMENT000000033… Indif… Sportif <NA> FALSE En service
6 BATIMENT000000033… Indif… Sportif <NA> FALSE En service
# ℹ more rows
# ℹ 25 more variables: date_creation <dttm>, date_modification <dttm>,
# date_d_apparition <date>, date_de_confirmation <date>, sources <chr>,
# identifiants_sources <chr>, methode_d_acquisition_planimetrique <chr>,
# methode_d_acquisition_altimetrique <chr>, precision_planimetrique <dbl>,
# precision_altimetrique <dbl>, nombre_de_logements <int>,
# nombre_d_etages <int>, materiaux_des_murs <chr>, …
Un exemple d’analyse sur un jeu de données très massif
: 4.65 secondes / : ~400 Mo en pic / : 64 Mo téléchargés en tout
A retenir
Arrow vous permet de lire très rapidement des jeux de données massifs et d’y appliquer des opérations d’agrégation simples.
DuckDB vous permet de lire très rapidement des jeux de données massifs et d’y appliquer presque tout type d’opération
Ces deux outils sont encore plus performants sur des jeux de données au format Parquet, que l’on est amené à trouver de plus en plus souvent sur internet (Insee, datasoft, etc.)
Seules adaptations nécessaires de votre code :
Arrow : remplacer la lecture par une indexation : open_dataset() à la place de read_XXX()
DuckDB : créer une connexion et y charger/indexer les données : con <- dbConnect(duckdb()) ; tbl(con, path) ou tbl_file(con, path) à la place de read_XXX(path)
Penser à “collecter” les données à la fin en format R si nécessaire : collect()
ducksf. Spatial Ops Faster Than sf and geos. (Kotov, 2024)
/
/
duckspatial : permet quelques opérations de “création de données” (buffer, centroides) et d’algèbre (intersection)
duckdbfs : puissant mais uniquement de l’algèbre spatial, intersection avec de nombreux prédicats (within, disjoin, contains…)
ducksf : conçu pour améliorer l’efficacité de certaines opérations de sf en passant temporairement en logique base de données
duckspatial
Téléchargement du fichier
library(sf)url_com <-"https://adresse.data.gouv.fr/data/contours-administratifs/2023/geojson/communes-100m.geojson"# lecture avec sfcommunes <-st_read(url_com, quiet =TRUE) st_crs(communes)# selection des communes d'un département com_sel <- communes %>%filter(departement =="90") %>%left_join(resume_commune, by =c("code"="COMMUNE"), copy =TRUE) %>%mutate(pct_logements = nb_logements /sum(nb_logements))
Jointure avec la table resume_commune
# selection des communes d'un département library(dplyr)com_sel <- communes %>%filter(departement =="90") %>%left_join(resume_commune, by =c("code"="COMMUNE"), copy =TRUE) %>%mutate(pct_logements = nb_logements /sum(nb_logements))
Passage en base de données avec duckspatial
# selection des communes d'un département library(duckspatial)ddbs_write_vector(con, com_sel, "com_sel_tbl", overwrite =TRUE)# Creer une vue pour la manipualtion avec dplyrcom_con <-tbl(con, 'com_sel_tbl')head(com_con)
duckspatial et SQL
Charger un csv et construire les géométries en SQL
# Télécharger le fichier CSV depuis le portail sncfurl_gares <-"https://ressources.data.sncf.com/api/explore/v2.1/catalog/datasets/gares-de-voyageurs/exports/csv?use_labels=true"library(duckdb)library(dplyr)# Création de la table DuckDB directement à partir du CSV distantdbExecute(con, paste0(" CREATE OR REPLACE TABLE gares_raw AS SELECT * FROM read_csv_auto('", url_gares, "', delim=';', header=true) "))
Mettre les données au propre et construire les géométries ponctuelles
# Transformation et création de la géométrie dans DuckDBdbExecute(con, " CREATE OR REPLACE TABLE gares_clean AS SELECT *, CAST(SPLIT_PART(\"Position géographique\", ',', 1) AS DOUBLE PRECISION) AS lat, CAST(SPLIT_PART(\"Position géographique\", ',', 2) AS DOUBLE PRECISION) AS lon, FROM gares_raw WHERE \"Position géographique\" IS NOT NULL")
Créer la table finale avec la géométrie au format GEOMETRY
dbSendQuery(con, " CREATE OR REPLACE TABLE gares_sf AS SELECT *, CAST(ST_Point(lon, lat) AS GEOMETRY) AS geom FROM gares_clean")
Connaitre les tables et faire une intersection
#### INTERSECTION AVEC LES COMMUNES #### quelles tables en mémoire ?dbGetQuery(con, "SHOW TABLES;")gares_sel <-ddbs_intersection(con, "com_sel_tbl", "gares_sf")
Qu’en est-il du spatial
* Des packages qui semblent complementaires … mais pas d’interropérabilité entre packages (duckdb, duckspatial etc..)
* On finit toujours pas remettre les données en mémoire
* Finalement pas de package tout à fait consolidé, mais des avancées prometeuses notamment pour duckdbfs